Michael Hodge, formerly MSc student at University of Bristol and currently PhD student at Cardiff University
Juliet Biggs, University of Bristol
Katsu Goda, University of Bristol
Willy Aspinall, University of Bristol
DOWNLOAD
THE CHALLENGE
The occurrence of a large earthquake involves a long strain accumulation process. The size of mapped fault segments can be used to estimate the characteristic magnitude via simple scaling relationships, and geodetic estimates of the rate of strain accumulation can be used to determine the associated recurrence interval. Such estimates of magnitude and frequency can be incorporated into a probabilistic hazard assessment. However, estimating characteristic magnitude and frequency of occurrence for an individual fault or fault system is a very uncertain proposition and depends strongly on assumptions. Testing sensitivity to different fault rupture scenarios is essential for contextualising a seismic hazard and interpreting results in the light of inherent uncertainty about physical mechanisms and our incomplete knowledge.
In this work, we illustrated how the geomorphology and geodesy of the Malawi Rift in Africa, a region with large seismogenic thicknesses, long fault scarps, slow strain rates, and a short historical record, can be used to assess hazard probability levels for large infrequent earthquakes through probabilistic seismic hazard analysis (PSHA).
WHAT WAS ACHIEVED
Our principal conclusion was that the Gutenberg-Richter magnitude-recurrence relationship, especially when based solely on a short instrumental catalogue, does not sufficiently capture seismicity potential in many tectonic settings. In areas where a characteristic earthquake model is more appropriate, geodetic and geomorphological information can be included to generate a synthetic earthquake catalogue suitable for probabilistic analysis. This approach, applied to the Malawi Rift, demonstrated that ignoring large, infrequent earthquakes tends to underestimate seismic hazard, particularly at the long vibration periods that disproportionally affect multi-storey constructions. We also found that the highest probabilistic hazard was associated with segmented ruptures.
HOW WE DID IT
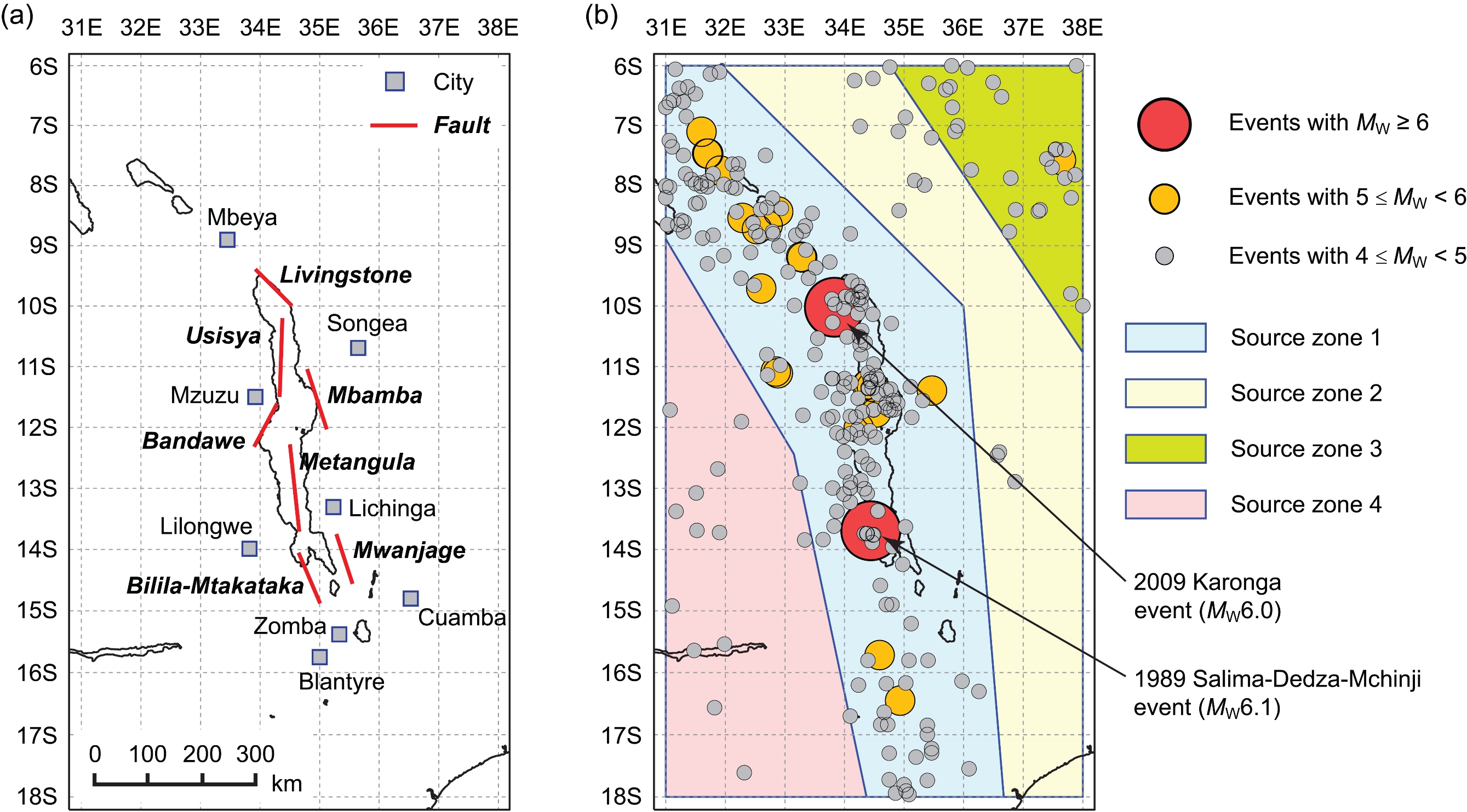
The East African Rift system is situated at the plate boundary between the Somalian and Nubian Plates, and extends over 4,000 km from the triple junction in Afar to fault-controlled basins in Malawi and south through Mozambique. The Malawi Rift lies on the southern branch of the East African Rift system and extends from Rungwe in the north to the Urema graben in the south. Relatively long fault lengths (>90 km) and wide seismogenic thickness (>30 km) in the Malawi Rift system suggest that earthquakes of M7.0 or greater are possible. For East Africa, a seismic hazard study conducted as part of the Global Seismic Hazard Assessment Programme (GSHAP) applied a conventional PSHA methodology by considering an available instrumental catalogue only. However, geomorphological evidence in the Malawi Rift indicates strongly potential for hosting characteristic earthquakes up to M8. Therefore, the current regional seismic hazard assessment may be significantly incomplete.
To address these issues, we explored the differences between the Gutenberg-Richter and characteristic earthquake models in the light of the geomorphological evidence for large events, taking account of uncertainties in fault dimensions, orientations, and segmentation to generate a synthetic source catalogue. Moreover, we investigated the impact of incorporating geomorphological information on the PSHA results for several cities around Lake Malawi by producing regional seismic hazard contour maps, uniform hazard spectra, and seismic disaggregation plots based on both instrumental and extended earthquake catalogues. In particular, we compared the seismic hazard results for (a) different earthquake catalogues (instrumental catalogue, continuous rupture catalogue, segmented rupture catalogue, and mixed rupture catalogue), (b) different return periods (500, 1,000, and 2,500 years), and (c) different ground motion parameters (peak ground acceleration and spectral accelerations at different vibration periods). We also tested the sensitivity of our results to the basic assumptions such as: the characteristic earthquake model, the chosen scaling relationships, fault segmentation, and neglecting any aseismic contribution to plate motion.
REFERENCES
Hodge, M., Biggs, J., Goda, K. and Aspinall, W. (2015). Assessing infrequent large earthquakes using geomorphology and geodesy: the Malawi Rift. Natural Hazards, 76(3). http://link.springer.com/article/10.1007%2Fs11069-014-1572-y